순열, 조합 구현
C++로 순열과 조합을 구현해보았다.
순열은 STL의 next_permutation과 prev_permutation을 쓰면 쉽게 구현할 수 있긴 하다. 하지만 하다보면 해당 원리를 이용해 조금 변형할 일이 생기기 마련......
순열과 조합은 보통 재귀를 이용해 구현한다.
◎ 조합
조합은 순열과 다르게 순서가 없는 나열이다. 그러니까 원소들을 중복 없이 뽑는다.
조합을 먼저 쓴 이유는 조합을 먼저 구해야 순열을 구할 수 있다.
우선 조합은 nCr로 n개 중에 r개를 뽑는 것이다.
만약 배열 {1,2,3,4,5}의 원소 중 3개씩 뽑는 조합을 만든다 했을 때 나올 수 있는 경우의 수는
(1,2,3) (1,2,4) (1,2,5) (1,3,4) (1,3,5) (1,4,5)
(2,3,4) (2,3,5) (2,4,5)
(3,4,5)
로 총 10개가 된다.
조합의 공식이 nPr / r! 임을 생각해보면 10개가 맞다.
#include <iostream>
using namespace std;
void Combination(int arr[], int n, int r, int index,int target, int comb_arr[])
{
if (r == 0)
{
// r개를 뽑기로 했는데 r개를 다 뽑은 경우
for (int i = 0; i < index; ++i)
{
cout << comb_arr[i];
}
cout << endl;
}
else if (target == n)
{
// target이 index를 초과=>종료
return;
}
else
{
//target 인덱스의 원소를 저장
comb_arr[index] = arr[target];
Combination(arr, n, r - 1, index + 1, target + 1, comb_arr); // 해당 원소를 선택
Combination(arr, n, r, index, target + 1, comb_arr); // 해당 원소를 선택하지 않음
}
}
int main()
{
int arr[5] = { 1,2,3,4,5 };
int n = 5;
int r = 3;
int* comb_arr = new int[5];
Combination(arr, 5, 3, 0,0 , comb_arr);
}
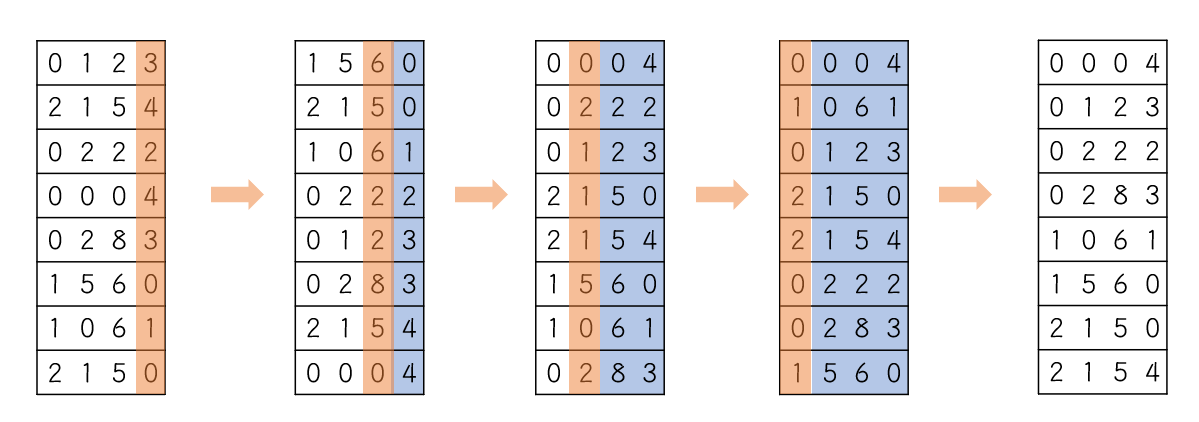
조합을 하기 위해서 배열을 돌면서 뽑는 경우와 안 뽑는 경우를 조사한다.
comb_arr는 빈 배열로 Combination 함수를 돌면서 뽑은 원소를 저장하는 배열이다.
Combination(arr, n, r - 1, index + 1, target + 1, comb_arr); // 해당 원소를 선택
Combination(arr, n, r, index, target + 1, comb_arr); // 해당 원소를 선택하지 않음
왜 두번 호출을 하냐면..
더보기
간단하게 말하면 다음 숫자를 선택하기 위해서라고 말할 수 있다.
먼저 해당 원소를 선택하는 함수를 1번, 선택하지 않는 함수를 2번 함수라고 했을 때 1,2,3과 1,2,4를 예를 들어보면
처음 호출 시 comb_arr[index] = arr[target]에는 index 초기값인 0, target 초기값인 0의 값이 들어가
comb_arr[0]에 1이, 그 다음 1번 함수를 호출하게 되면서 r은 2, index는 1, taget 은 1인 상태로 comb_arr[1]에는 2가 들어가게 된다.
그 다음 1번 함수의 호출로 인해 들어간 상태에는
index와 target은 2, r은 1이 된다. 따라서 arr[2]의 값인 3이 comb_arr[2]에 들어가게 되며
한 번 더 1번 함수를 호출하게 되면 r이 0이므로 123이 출력된다.
여기서 알아둘 것은 재귀함수 호출이므로 아직까지 2번 함수는 한 번도 실행되지 않았다.
출력이 끝난 해당 함수는 종료되고 그때 이제 2번 함수가 호출이 되는데 가장 마지막의 r값인 1의 값을 가지고 있으며 index는 2, target이 2인 상태의 Combination상태가 호출되는 것이다.
이 상황에서 2번 함수가 호출되면 target의 값만 1 증가하기 때문에
comb_arr[index] = arr[target]; 줄을 수행하고 나면 comb_arr[2]에는 arr[3]의 값이 들어가게 된다.
그 후 다시 1번 함수를 호출해서 들어간 함수 내부에서 r이 0이 되므로 출력을 하는 것이다.
이 부분을 보면 위의 줄은 target에 위치한 원소를 원소를 뽑는 부분, 밑의 줄은 원소를 선택하지 않는 부분이다.
또한 target은 함수 호출 시 항상 1을 증가시켜서 넘겨야 순회하는 역할을 할 수 있다.
선택할 때는 r을 1 감소시키고 index를 1 증가시키며 선택하지 않을 때는 r을 그대로, index도 그대로 넣고 호출한다.
index를 증가시키는 이유는 현재 target이 가리키는 원소를 선택하고 다음 index를 선택하기 위함이며
증가시키지 않는 것은 현재 target이 가리키는 원소를 선택하지 않고 현재 index에 다른 원소를 선택하기 위함이다.
이렇게 순회를 하는 도중, 다 뽑은 경우인 r=0과 r개를 다 뽑았지만 arr의 모든 원소를 다 검사했을 때인 target = n일 때이다. 후자의 경우 실패이므로 아무것도 하지 않고 return하게 된다.
◎ 순열
순열은 순서가 있는 나열이다.
우선 n개 중에 n개를 뽑는 순열을 보면
void Swap(int arr[], int num1, int num2)
{
int temp = arr[num1];
arr[num1] = arr[num2];
arr[num2] = temp;
}
void Permutation(int arr[], int index, int arr_size)
{
// 탈출!
if (arr_size - 1 == index)
{
for (int i = 0; i < arr_size; ++i)
{
cout << arr[i];
}
cout << endl;
return;
}
for (int i = index; i < arr_size; ++i)
{
Swap(arr, index, i);
Permutation(arr,index + 1, arr_size);
Swap(arr, index, i);
}
}
int main()
{
int arr[5] = { 1,2,3,4,5 };
Permutation(arr, 0, sizeof(arr) / sizeof(int));
}
(1,2,3,4,5) 의 배열에서 5개 중 5개를 뽑는 순열을 구하면 순열 공식에 의해 총 120개가 나오게 된다.
arr배열 자체를 위에서 구한 조합을 이용해 정렬하는 것이다.
먼저 swap을 이용해서 index번째의 자리 수가 1,2,3,4,일 때를 조사한다. index번째 자리를 선택한 후에 재귀를 통해 그 다음 자리를 선택하다가 arr의 마지막을 가리키면 끝이 난다.
재귀 후 다시 swap으로 바꿔준 값을 원상복구를 하면 다시 각 자리 수가 1일 때, 2일 때, 3일 때, 4일 때를 모두 조사할 수 있다.
n개에서 n개를 뽑는 경우를 구했으니 이제 n개 중 r개를 뽑는 경우를 구하면 되는데
이건 위에서 구한 조합을 이용하면 된다. 먼저 nCr을 이용해 n개 중에 r개를 뽑은 후에 r개의 수로 이루어진 숫자들을 permutation을 이용해서 정렬해주면 된다.
void Swap(int arr[], int num1, int num2)
{
int temp = arr[num1];
arr[num1] = arr[num2];
arr[num2] = temp;
}
void Permutation(int arr[], int index, int arr_size)
{
// 탈출!
if (arr_size - 1 == index)
{
for (int i = 0; i < arr_size; ++i)
{
cout << arr[i];
}
cout << endl;
return;
}
for (int i = index; i < arr_size; ++i)
{
Swap(arr, index, i);
Permutation(arr,index + 1, arr_size);
Swap(arr, index, i);
}
}
void Combination(int arr[], int n, int r, int index, int target, int comb_arr[])
{
if (r == 0)
{
Permutation(comb_arr, 0, 3);
cout << endl;
}
else if (target == n)
{
return;
}
else
{
comb_arr[index] = arr[target];
Combination(arr, n, r - 1, index + 1, target + 1, comb_arr);
Combination(arr, n, r, index, target + 1, comb_arr);
}
}
int main()
{
int arr[5] = { 1,2,3,4,5 };
int* comb_arr = new int[5];
Combination(arr, 5, 3, 0,0 , comb_arr);
}
혹시 이 포스팅을 보시는 분께..
더보기
순열 함수를 호출하는 부분에서 원래 배열의 '크기' 즉 인자가 몇 개있는지를 구해야 하는데 나는 포인터로 넘겨받고 있어 sizeof를 쓸 수 없고 comb_arr의 사이즈를 구하는 다른 방법을 쓰기 귀찮아서 그냥 3개를 뽑을 거라 위의 코드에는 3을 arr_size로 넘겨줬다.
참고 자료;
it-earth.tistory.com/53
onsil-thegreenhouse.github.io/programming/algorithm/2018/04/05/permutation_combination/