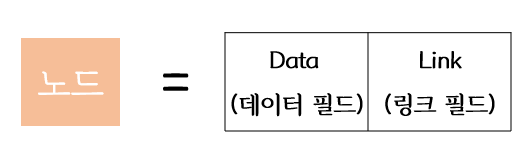
트리
Tree
트리는 객체간의 관계를 표현하는 자료구조인 그래프의 일종이다.
◎ 트리란
트리는 노드들이 가지처럼 연결된 비선형 계층적 자료구조이다.
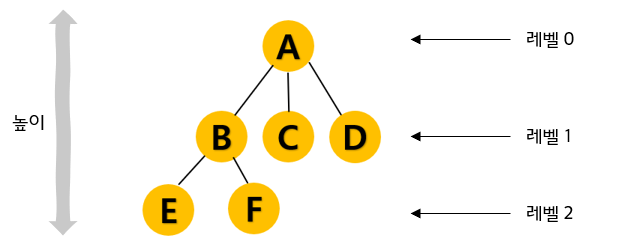
노드 : 트리의 구성요소에 해당하는 A,B, C, D, E, F와 같은 요소
간선 : 노드와 노드를 연결하는 연결선
루트 노드 : 트리 구조에서 최상위에 존재하는 A와 같은 노드
단말 노드 : 아래로 또 다른 노드가 연결되어 있지 않은 가장 마지막 (E,F,C,D와 같은) 노드
내부 노드 : 단말 노드를 제외한 모든 노드
레벨 : 각 층 별로 숫자를 매긴 것
높이 : 트리의 최고 레벨
◎ 이진트리

이진트리란 루트 노드를 중심으로 두 개의 서브 트리로 나누어지며 나누어진 두 서브 트리도 모두 이진 트리여야 한다.
즉, A를 기준으로 B,D,E가 왼쪽 서브 트리 C,F,G가 오른쪽 서브트리이며 각각의 서브 트리들도 이진 트리여야 한다.
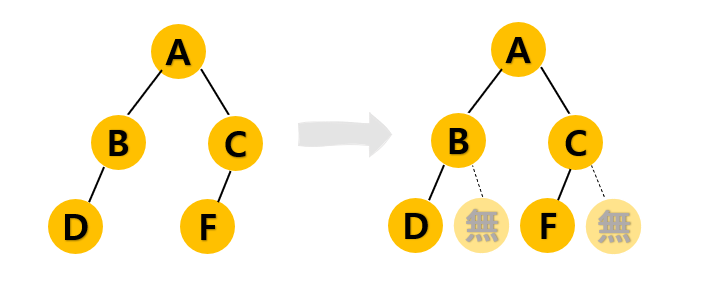
여기서 왼쪽과 같은 트리도 이진트리가 된다.
노드가 위치할 수 있는 곳에 노드가 존재하지 않으면 공집합 노드가 존재하는 것으로 간주해 공집합 노드도 '노드로 인정'하기 때문이다.
이진 트리는 여러 분류로 나뉠 수 있는데 그 중 완전 이진트리와 포화 이진트리가 존재한다.

포화 이진 트리는 위의 그림과 같이 모든 레벨이 꽉 차 있으며 노드를 더 추가하려면 레벨을 늘려야 하는 트리이다.
이 포화 이진 트리에서 레벨을 하나 더 늘려 H와 I를 추가한 다음 이진 트리를 보면 포화 이진 트리처럼 모든 레벨이 꽉 찬 상태는 아니지만 차곡차곡 빈 틈 없이 노드가 채워진 이진 트리가 된다.
여기서의 '차곡차곡 빈 틈 없이'는 노드가 위에서 아래로, 그리고 왼쪽에서 오른쪽의 순서대로 채워졌다는 의미가 된다.
이 트리가 바로 완전 이진 트리이다.
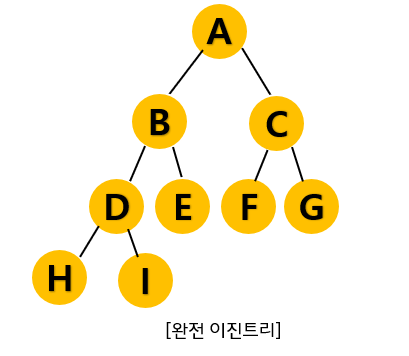
완전 이진트리는 임의의 두 단말 노드의 레벨 차이가 1이하인 경우이며 위의 그림과 같이 왼쪽에서 오른쪽으로 채워진 이진트리를 뜻한다.
레벨 n까지의 모든 노드수는 2^n -1개이다.
◎ 트리의 순회
트리의 순회란 트리에 속하는 모든 노드를 한 번씩 방문하는 것이다. 트리의 순회 방식에는 전위, 중위, 후위 방식이 있다.
루트를 방문하는 작업을 V, 왼쪽과 오른쪽 서브 트리를 방문하는 작업을 각각 L과 R이라고 하면
전위는 VLR, 중위는 LVR, 후위는 LRV 이다.
트리의 순회는 쉬워보이지만 복잡한 노드의 트리인 경우 생각보다 헷갈리게 된다.

다음과 같은 사진이 있을 때 전위, 중위, 후위 순회의 결과는 다음과 같다.
전위 순회 : F,B,A,D,C,E,G,I,H
중위 순회 : A,B,C,D,E,F,G,H,I
후위 순회 : A,C,E,D,B,H,I,G,F
전위 순회
Void preorder(TNode *n)
{
If( n!= NULL )
{
Printf(“[%c]”, n->data);
Preorder(n->left);
Preorder(n->right);
}
}
중위 순회
Void inorder(TNode *n)
{
If( n!= NULL )
{
inorder(n->left);
Printf(“[%c]”, n->data);
inorder (n->right);
}
}
후위 순회
Void postorder(TNode *n)
{
If( n!= NULL )
{
postorder(n->left);
postorder (n->right);
Printf(“[%c]”, n->data);
}
}
참고로 이 트리의 전위순회 방식을 일반화시킨 그래프의 정점 순회 방법이 깊이 우선탐색 (DFS)이다.
탐색 도중에 인접된 모든 정점이 이미 방문된 정점을 만났을 때 바로 이전에 방문한 정점으로 돌아가기 위해 스택을 사용한다.
참고 자료;
윤성우의 열혈 자료구조 (저; 윤성우, 출판; 오렌지 미디어)
https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%A6%AC_%EC%88%9C%ED%9A%8C
'알고리즘 & 자료구조 > 자료구조' 카테고리의 다른 글
| [자료구조] 스택 C언어로 구현하기 (배열) (0) | 2021.06.26 |
|---|---|
| [자료구조] 스택 C언어로 구현하기 (연결리스트) (0) | 2020.10.16 |
| [자료구조] 연결리스트(Linked-List) (0) | 2020.10.16 |
| [자료구조] 트라이(Trie) 트리 (0) | 2020.10.07 |